GID2017-1 | Estructuras de Datos y Algoritmos (INEDA)
Proyecto 2018
Hacia la personalización del estudio: Técnicas Inteligentes para identificar los elementos de mayor dificultad de las asignaturas
Resumen
El objetivo de este proyecto fue diseñar una metodología para identificar los elementos que resultan más dificultosos para los alumnos en las distintas asignaturas. De esta forma se pretende optimizar los resultados de mejora obtenidos con la producción de nuevos materiales al centrarlos en dichos elementos más problemáticos. Se propuso desarrollar una metodología que permita realizar un análisis estadístico de los resultados de pruebas de evaluación de cursos pasados relacionando aspectos y temas de las preguntas con los resultados. Se propuso así mismo extraer automáticamente información con técnicas avanzadas de procesamiento del lenguaje natural, en las que el grupo es experto, para realizar un análisis de los comentarios y preguntas más frecuentes realizadas por los alumnos en los foros. Los resultados de ambos enfoques se pretenden combinar en el diseño de una metodología conjunta. Estás técnicas se evaluaron sobre algunas de las asignaturas impartidas por el grupo para las que disponemos de información recogida a los largo de los años. Sin embargo, el objetivo fue diseñar una metodología exportable a cualquier otra asignatura. Los resultados obtenidos también fueron evaluados por alumnos mediante encuestas.
Objetivos
- [OBJ.1] Identificar los elementos que resultan de mayor dificultad para los estudiantes en las asignaturas.
- [OBJ.2] Diseñar una metodología general aplicable a cualquier asignatura que permita exportar los resultados del proyecto.
- [OBJ.3] Construir colecciones anotadas con etiquetas que caractericen el tipo de pregunta de cada examen (de manera que se puedan extraer relaciones estadísticas), y con los resultados de los estudiantes anonimizados para cada pregunta.
- [OBJ.4] Diseñar técnicas de análisis estadístico para analizar las combinaciones de elementos en los que los estudiantes obtienen peores resultados.
- [OBJ.5] Construir un corpus de documentos recogidos en foros, correo, preguntas frecuentes, etc. relativos a las asignaturas involucradas.
- [OBJ.6] Aplicar técnicas de procesamiento del lenguaje natural para extraer información de los documentos con comentarios y preguntas sobre las asignaturas.
- [OBJ.7] Diseñar una metodología de evaluación mediante encuestas a los alumnos de las asignaturas involucradas.
- [OBJ.8] Difusión y publicación de los resultados obtenidos que los hagan exportables a otras asignaturas y a otros ámbitos.
Experiencia de innovación
La metodología seguida consta de los siguientes puntos principales:
Preparación de datos: selección de etiquetas. Una parte fundamental del trabajo fue la preparación de colecciones de las que extraer relaciones y datos estadísticos. En primer lugar se estableció por el equipo del proyecto un conjunto de etiquetas relevantes que han sido asignadas a las preguntas de examen para caracterizarlas. Entre los indicadores están el tema o temas de la asignatura con los que se relaciona la pregunta, pero también se han considerado otros aspectos, como el carácter más teórico o práctico de la pregunta, así como los conocimientos previos necesarios que no sean parte de la asignatura.
Preparación de datos: anotación de la colección. Una vez establecidas las etiquetas consideradas más relevantes para el estudio se ha realizado un etiquetado manual de las preguntas de los exámenes recogidos en cursos anteriores en las distintas asignaturas involucradas en el proyecto. Esta colección de preguntas, etiquetas y resultados de los estudiantes para cada una de ellas es un producto valioso resultante del proyecto.
Análisis estadísticos de los datos. En una segunda fase, utilizando la colección preparada, se han diseñado diversos análisis estadísticos, desarrollando programas para aplicarlos a los datos de prueba. Los resultados de estos análisis se han estudiado detalladamente para alcanzar las conclusiones a las que ha dado lugar el proyecto.
Al finalizar el proyecto se presentó a los estudiantes de la asignatura considerada una encuesta para poder contrastar los resultados obtenidos con el análisis de los datos y la percepción de los estudiantes.
Resultados obtenidos
A partir de los datos recogidos y anotados y de la metodología diseñada se han realizado los siguientes análisis estadísticos:
Tasas de éxito, fallos y cuestiones sin responder
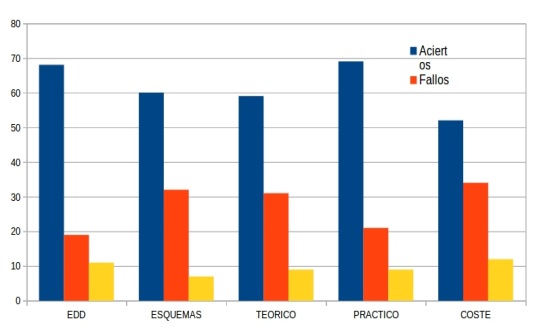
En primer lugar se analizaron los resultados de las etiquetas más generales, Estructuras de datos (EDD), Esquemas, carácter práctico o teórico y si se trata de una cuestión relacionada con coste algorítmico. Se encontraron diferencias apreciables entre ellos. Por ejemplo comparando las EDD y los esquemas vemos que mientras las primeras están cerca de un 70% de aciertos, los esquemas apenas pasan de 60. También hay diferencias entre el carácter práctico y teórico de las cuestiones, que reflejan que las cuestiones prácticas tienden a resultar más sencillas, con casi 10 puntos de diferencia. También observamos que las cuestiones de coste algorítmico, tienden a resultar difíciles.
También se compararon distintos temas dentro de la parte de EDD y dentro de la parte de esquemas algorítmicos.

Entre las EDD se ha visto que las cuestiones relacionadas con árboles de recubrimiento tienden a resultar más sencillas. Por el contrario, las cuestiones relacionadas con tablas hash, con la identificación de las componentes conexas en un grafo y con los puntos de articulación de un grafo, tienden a resultar claramente más complejas, llegando a estar por debajo del 50%.
Entre los esquemas algorítmicos también hay diferencias importantes.

Por ejemplo, el algoritmo voraz de minimización del tiempo en el sistema alcanza cerca del 90% de tasa de acierto, frente a quicksort, que no llega al 50%. Observamos que los algoritmos voraces, incluyendo Prim y Kruskal tienden a resultar más fáciles, pero hay que tener en cuenta que las cuestiones sobre estos algoritmos suelen presentarse de forma práctica.
Significatividad estadística
Hay que tener en cuenta que no todos los datos son igual de representativos. Hay temas que se han preguntado con mucha más frecuencia que otros. Por eso consideramos importante asegurarnos de que los datos sean significativos y por tanto las conclusiones fiables. Por ello, se investigaron los intervalos en los que esperamos que se encuentre la probabilidad.
Se comprobó que para las etiquetas generales, los rangos de las probabilidades son muy estrechos, lo que confirma que los valores obtenidos son significativos.

En el caso de las estructuras de datos, algunos temas como los puntos de articulación o la identificación de componentes conexas, tienen un rango mucho más amplio, indicando que los valores para estos temas no son tan significativos, aunque lo son para la mayoría de los temas.
Finalmente, en los esquemas y algoritmos los intervalos de confianza también son reducidos excepto para mergesort, tema del que ha habido pocas cuestiones.
Correlación con el aspecto teórico o práctico de las cuestiones planteadas
Otra cuestión que hemos investigado es la existencia de correlación entre el carácter práctico o teórico de las cuestiones y los resultados. Para investigarlo hemos aplicado el test chi-square de Pearson.
Algunos de los resultados obtenidos son los que muestra la siguiente tabla:
| ETIQUETA | SIGNIFICANCIA |
| Esquemas | <2.2·e16 |
| Estructuras de datos | 0.0015 |
| Grafos | 0.0005 |
| Hash | 0.0028 |
| Divide y vencerás | 0.59 |
Se puede comprobar que la significancia de la correlación es muy alta en todos los casos, excepto para Divide y Vencerás. Resulta este un caso especial porque por una parte incluye cuestiones de carácter práctico, como quicksort, pero a su vez, quicksort, a pesar de su carácter práctico, es uno de los temas de mayor dificultad para los estudiantes, como pudimos ver antes en los resultados.
Conclusiones
De los resultados se concluye que existen diferencias significativas en la dificultad que presentan los distintos temas de una asignatura para los estudiantes. No se trata de diferencias puntuales que dependen de la convocatoria concreta o de cómo se hayan planteado las cuestiones correspondientes. Las diferencias se mantienen a lo largo del tiempo y se confirman en los datos agregados. En el caso concreto de la materia relacionada con Estructuras de datos y algoritmos se constata que:
-
Las cuestiones relacionadas con algoritmia resultan más difíciles para los estudiantes.
-
En las cuestiones teóricas también tienden a obtener peores resultados.
-
Las cuestiones de coste computacional son particularmente dificultosas.
La metodología propuesta es exportable a otras asignaturas y disciplinas. Para salvar el coste que supone la necesidad de datos que incluyan cuestiones anotadas con los temas asociados, un paso necesario que abordaremos en el futuro es la automatización de este proceso.
Difusión y explotación
A continuación detallamos las publicaciones resultado de este proyecto de innovación:
doi: 10.21125/iceri.2018.2243
Publisher: IUED (Instituto Universitario de Educación a Distancia)
Transferencia y divulgación
Los resultados de este proyecto se presentaron en:
- La V Jornada de Innovación y Tecnologías Educativas (JITE-2019) de la UNED:
- Programa de Radio de CanalUNED:
Análisis de la dificultad del temario en asignaturas de algoritmia
- Las X Jornadas de Investigación en Innovación Docente de la UNED. Innovación educativa en la era digital (línea 2) de la UNED:
Análisis de la dificultad de elementos de algoritmia para los alumnos
Primeros análisis de la dificultad de elementos de algoritmia para alumnos